
The Incus team is pleased to announce the release of Incus 6.22!
This is quite the busy release with a lot of changes all across the board on top of a large quantities of bugfixes. There should be something for everyone!
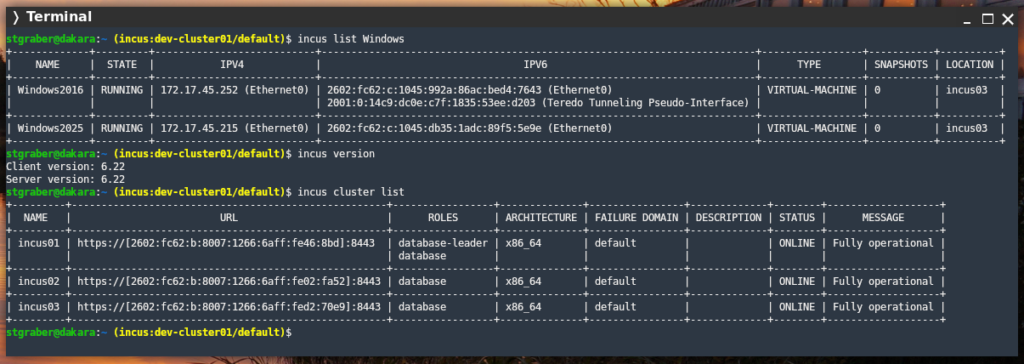
On the feature front, the highlights for this release are:
- vsock support for the WIndows agent
- Direct backup retrieval
- Disk-only snapshot restoration
- Dedicated storage volume for server logs
- QCOW2 storage improvements
- lvmcluster storage pool resizing
- Automatic snapshot removal on restore with lvmcluster
- Full USB controller passthrough in unix-hotplug
- Certificate information in the authorization scriptlet
- VM fast reboot
- Image server URL restrictions in projects
- URL based imports in incus-migrate
- Multi-domain certificates with ACME
- Control of trusted property on SR-IOV NICs
- Additional cluster member states to track evacuation
- Cluster restore without instance migration
- Instance boot time metrics
The full announcement and changelog can be found here.
And for those who prefer videos, here’s the release overview video:
You can take the latest release of Incus up for a spin through our online demo service at: https://linuxcontainers.org/incus/try-it/
And as always, my company is offering commercial support on Incus, ranging from by-the-hour support contracts to one-off services on things like initial migration from LXD, review of your deployment to squeeze the most out of Incus or even feature sponsorship. You’ll find all details of that here: https://zabbly.com/incus
Donations towards my work on this and other open source projects is also always appreciated, you can find me on Github Sponsors, Patreon and Ko-fi.
Enjoy!
 Github
Github Twitter
Twitter LinkedIn
LinkedIn Mastodon
Mastodon