The Linux Containers project maintains Long Term Support (LTS) releases for its core projects. Those come with 5 years of support from upstream with the first two years including bugfixes, minor improvements and security fixes and the remaining 3 years getting only security fixes.
This is now the sixth round of bugfix releases for LXC, LXCFS and Incus 6.0 LTS.
LXC
LXC is the oldest Linux Containers project and the basis for almost every other one of our projects. This low-level container runtime and library was first released in August 2008, led to the creation of projects like Docker and today is still actively used directly or indirectly on millions of systems.
Improved systemd scope handling for unprivileged containers
Added support for OpenRC as an init system
Fixed a data transfer race in the attach logic when using io_uring
Fixed handling of lxc.cap.keep and lxc.cap.drop in configuration
LXCFS
LXCFS is a FUSE filesystem used to workaround some shortcomings of the Linux kernel when it comes to reporting available system resources to processes running in containers. The project started in late 2014 and is still actively used by Incus today as well as by some Docker and Kubernetes users.
Fix issue causing the cgroup2 mount flags to be changed on startup
Incus
Incus is our most actively developed project. This virtualization platform is just over a year old but has already seen over 3500 commits by over 120 individual contributors. Its first LTS release made it usable in production environments and significantly boosted its user base.
Override-able configuration and devices on backup import
database-client cluster role
Support for parent=none on OVN uplink networks
Cluster groups in configuration preseed
Systemd credentials
Storage volume file operations
Export of ISO volumes
BPF token delegation
MacOS support for the Incus agent
VirtIO sound card in VMs
Support for detaching USB devices without removing them
dns.mode for OVN network
Configurable MAC address patterns
Extended IncusOS CLI
Initial SELinux support
Improved Windows agent support
Serial devices in the resources API
Bandwidth limits on OVN NICs
Support for multi-object deletion in most CLI commands
Ability to turn off passthrough of PCI firmware to VM
PKCS12 generation in the CLI
Option for raw units in CLI CSV output
QCOW2 formatted volumes on clustered LVM
Standalone incus cluster join command
Configuration file for the VM agent
Reverse DNS records in OVN
incus wait command
Automatic SR-IOV selection for network interfaces
attached and connected properties on network interfaces
Parallel instance startup
Network restrictions through OIDC claims
Better support for the SOA in network zones
Support for forceful (recursive) file deletion in API
vsock support for the WIndows agent
Direct backup retrieval
Disk-only snapshot restoration
Dedicated storage volume for server logs
QCOW2 storage improvements
lvmcluster storage pool resizing
Automatic snapshot removal on restore with lvmcluster
Full USB controller passthrough in unix-hotplug
Certificate information in the authorization scriptlet
VM fast reboot
Image server URL restrictions in projects
URL based imports in incus-migrate
Multi-domain certificates with ACME
Control of trusted property on SR-IOV NICs
Additional cluster member states to track evacuation
Cluster restore without instance migration
Instance boot time metrics
What’s next?
We’re expecting one last round of LTS bugfix release for the 6.0 branches around May/June 2026 following the release of the 7.0 LTS in April 2026. After that, the 6.0 branches will be in security-only maintenance mode for the remaining three year of support while we focus our bugfix and improvements efforts on the 7.0 branches.
The Linux Containers project maintains Long Term Support (LTS) releases for its core projects. Those come with 5 years of support from upstream with the first two years including bugfixes, minor improvements and security fixes and the remaining 3 years getting only security fixes.
This is now the fifth round of bugfix releases for LXC, LXCFS and Incus 6.0 LTS.
LXC
LXC is the oldest Linux Containers project and the basis for almost every other one of our projects. This low-level container runtime and library was first released in August 2008, led to the creation of projects like Docker and today is still actively used directly or indirectly on millions of systems.
Fixes a regression introduced in LXC 6.0.4 which was causing some hooks to fail due to no-new-priv handling
Removed support for building with the bionic C library (Android) as it hadn’t been functional for a long time
Fixed handling of the container_ttys environment variable
Added support for both move and nosymfollow mount options
Improved testsuite coverage
LXCFS
LXCFS is a FUSE filesystem used to workaround some shortcomings of the Linux kernel when it comes to reporting available system resources to processes running in containers. The project started in late 2014 and is still actively used by Incus today as well as by some Docker and Kubernetes users.
There are no significant changes in this release, only a couple of minor changes to our CI scripts. We are still pushing a LXCFS update out to keep versions in sync between LXC, LXCFS and Incus, but this release is effectively identical to 6.0.4.
Incus
Incus is our most actively developed project. This virtualization platform is just over a year old but has already seen over 3500 commits by over 120 individual contributors. Its first LTS release made it usable in production environments and significantly boosted its user base.
CLI support for server-side filtering on all collections
Windows agent support for VMs
Improvements support to incus-migrate (extra disks, OVA, …)
SFTP API support on custom storage volumes
Support for publishing instances as split images
S3 upload of instances and volume backups
More flexible snapshot configuration
What’s next?
We’re expecting another LTS bugfix release for the 6.0 branches by the end of 2025. In the mean time, Incus will keep going with its usual monthly feature release cadence.
Thanks
This LTS release update was made possible thanks to funding provided by the Sovereign Tech Fund (now part of the Sovereign Tech Agency).
The Sovereign Tech Fund supports the development, improvement, and maintenance of open digital infrastructure. Its goal is to sustainably strengthen the open source ecosystem, focusing on security, resilience, technological diversity, and the people behind the code.
As a reminder, Zabbly is the company I created for my freelance work. Most of it is Incus related these days, though I also make and publish some mainline kernel builds, ZFS packages and OVS/OVN packages!
On top of that, Zabbly also owns my various ARIN resources (ASN, allocations, …) as well as my hosting/datacenter contracts.
Through Zabbly I offer a mix of by-the-hour consultation with varying prices depending on the urgency of the work (basic consultation, support, emergency support) as well as fixed-cost services, mostly related to Incus (infrastructure review, migration from LXD, remote or on-site trainings, …).
Zabbly is also the legal entity for donations related to my open source work, currently supporting:
And lastly, Zabbly also runs a Youtube channel covering the various projects I’m involved with. That part grew quite a bit over the past year, with subscriber count up 75%, frequent live streams and release videos. The channel is now part of the YouTube Partner program.
FuturFusion
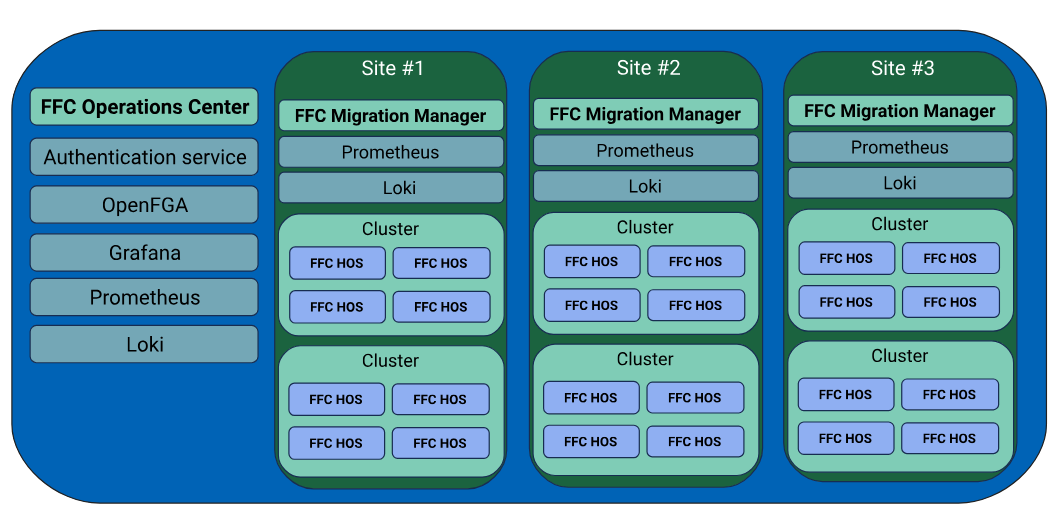
In addition to the work I’m doing through Zabbly. I’m also the CTO and co-founder of FuturFusion.
FuturFusion is focused on providing a full private cloud solution to enterprise customers, primarily those looking for an alternative to VMware. The solution is comprised of:
Incus clusters
Hypervisor OS (based on Incus OS)
Operations Center (provisioning, global inventory, update management, ..)
While Zabbly is just a one person show, FuturFusion has a global team and offers 24/7 support.
All components of the FuturFusion Cloud suite are fully open-source (Apache 2.0). FuturFusion customers get access to fully tested and supported builds of the software stack.
Incus
A lot has been going on with Incus over the past year!
Some of the main feature highlights are:
OCI application containers support
Automatic cluster re-balancing
Windows support for the VM agent
Linstor storage driver
Network address sets
A lot of OVN improvements (native client, ECMP for interconnect, load-balancer monitoring, ability to run isolated networks, inclusion of physical interfaces into OVN, …)
A lot of VM improvements (OS reporting, baseline CPU calculation, console history, import of existing QCOW2/VMDK/OVA images, live-migration of VM storage, screenshot API, IOMMU support, USB virtual devices, memory hotplug, …)
We also acquired (through Zabbly) our own MAC address prefix and transitioned all our projects over to that!
The University of Texas in Austin once again decided to actively contribute to Incus, leading to dozens of contributions by students, clearing quite a bit of our feature request backlog.
And I can’t talk about recent Incus work without talking about Incus OS. This is recent initiative to build our own immutable OS image, just to run Incus. It’s designed to be as safe as possible and easy to operate at large scale. I recently traveled to the Linux Security Summit to talk about it.
Two more things also happened that are definitely worth mentioning, the first is the decision by TrueNAS Scale to use Incus as the built-in virtualization solution. This has introduced Incus to a LOT of new people and we’re looking forward to some exciting integration work coming very soon!
The other is a significant investment from the Sovereign Tech Fund, funding quite a bit of Incus work this year, from our work on LTS bugfix releases to the aforementioned Windows agent and a major refresh of our development lab!
NorthSec
NorthSec is a yearly cybersecurity conference, CTF and training provider, usually happening in late May in Montreal, Canada. It’s been operating since 2013 and is now one of the largest on-site CTF events in the world along with having a pretty sizable conference too.
There are two main Incus-related highlights for NorthSec this year.
First, all the on-site routing and compute was running on Incus OS. This was still extremely early days with this being (as far as I know) the first deployment of Incus OS on real server hardware, but it all went off without a hitch!
The second is that we leaned very hard on Infrastructure As Code this year, especially on the CTF part of the event. All challenges this year were published through a combination of Terraform and Ansible, using their respective providers/plugins for Incus. The entire CTF could be re-deployed from scratch in less than an hour and we got to also benefit from pretty extensive CI through Github Actions.
For the next edition we’re looking at moving more of the infrastructure over to Incus OS and make sure that all our Incus cluster configuration and objects are tracked in Terraform.
Conferences
Similar to last year, I’ve been keeping conference travel to a lower amount than I was once used to 🙂
But I still managed to make it to:
Linux Plumbers Conference 2024 (in Vienna, Austria)
Ran the containers & checkpoint/restore micro-conference and talked about immutable process tags
This will likely be it as far as conference travel for 2025 as I don’t expect to make it in person to Linux Plumbers this year, though I intend to still handle the CFP for the containers/checkpoint-restore micro-conference and attend the event remotely.
What’s next
I expect the coming year to be just as busy as this past year!
Incus OS is getting close to its first beta, opening it up to wider usage and with it, more feature requests and tweaks! We’ve been focusing on its use for large customers that get centrally provisioned and managed, but the intent is for Incus OS to also be a great fit for the homelab environment and we have exciting plans to make that as seamless as possible!
Incus itself also keeps getting better. We have some larger new features coming up, like the ability to run OCI images in virtual machines, the aforementioned TrueNAS storage driver, a variety of OVN improvements and more!
And of course, working with my customers, both through Zabbly and at FuturFusion to support their needs and to plan for the future!
The Linux Containers project maintains Long Term Support (LTS) releases for its core projects. Those come with 5 years of support from upstream with the first two years including bugfixes, minor improvements and security fixes and the remaining 3 years getting only security fixes.
This is now the fourth round of bugfix releases for LXC, LXCFS and Incus 6.0 LTS.
LXC
LXC is the oldest Linux Containers project and the basis for almost every other one of our projects. This low-level container runtime and library was first released in August 2008, led to the creation of projects like Docker and today is still actively used directly or indirectly on millions of systems.
New LXC_IPV6_ENABLE lxc-net configuration key to turn IPv6 on/off
Fixed ability to attach to application containers with non-root entry point
LXCFS
LXCFS is a FUSE filesystem used to workaround some shortcomings of the Linux kernel when it comes to reporting available system resources to processes running in containers. The project started in late 2014 and is still actively used by Incus today as well as by some Docker and Kubernetes users.
Properly handle SLAB reclaimable memory in meminfo
Handle empty cpuset strings
Fix potential sleep interval overflows
Incus
Incus is our most actively developed project. This virtualization platform is just over a year old but has already seen over 3500 commits by over 120 individual contributors. Its first LTS release made it usable in production environments and significantly boosted its user base.
Due to the nature of this tool, it doesn’t get LTS releases as its feature set is extremely stable but still needs to receive very frequent updates to handle changes in the various Linux distributions that it builds. Distrobuilder 3.2 was released at the same time as the LTS releases, providing an up to date snapshot of that project.
systemd generator handles newer Linux distributions
Support for Alpaquita
What’s next?
We’re expecting another LTS bugfix release for the 6.0 branches in the third quarter of 2025. In the mean time, Incus will keep going with its usual monthly feature release cadence.
Thanks
This LTS release update was made possible thanks to funding provided by the Sovereign Tech Fund (now part of the Sovereign Tech Agency).
The Sovereign Tech Fund supports the development, improvement, and maintenance of open digital infrastructure. Its goal is to sustainably strengthen the open source ecosystem, focusing on security, resilience, technological diversity, and the people behind the code.
A lot has happened in 2024 for the Incus project, so I thought it’d be interesting to see where we started, what we did and where we ended up after that very busy year, then look forward to what’s next in 2025!
Where we started
We began 2024 right on the heels of the Incus 0.4 release at the end of December 2023.
This means that effectively everything that made it into Incus in 2024 originated directly from the Incus community. There is one small exception to that as LXD 5.0 LTS still saw some activity and as that’s still under Apache 2.0, we were able to import a few commits (83 to be exact) from that branch.
Incus 6.0 LTS was released at the beginning of April, alongside LXC and LXCFS 6.0 LTS. All of which get 5 years of security support.
That was a huge milestone for Incus as it now allowed production users who don’t feel like going through an update cycle every month to switch over to Incus 6.0 LTS and have a stable production release for the years to come.
It also provides a much easier packaging target for Linux distributions as the monthly releases can be tricky to follow, especially when they introduce new dependencies.
Today, Incus 6.0 LTS represents around 50% of the Incus user base.
Notable feature additions
It’s difficult to come up with a list of the most notable new features because so much happened all over the place and deciding what’s notable ends up being very personal and subjective, depending on one’s usage of Incus, but here are a few!
Application container support (OCI), gives us the ability to natively run Docker containers on Incus
Clustered LVM storage backend, adds support for iSCSI/NVMEoTCP/FC storage in clusters
Network integrations (OVN inter-connect), allows for cross-cluster overlay networking
Automatic cluster re-balancing, simplifies operation of large clusters
Performance improvements
As more and more users run very large Incus systems, a number of performance issues were noticed and have been fixed.
An early one was related to how Incus handled OVN. The old implementation relied on the OVN command line tools to drive OVN database changes. This is incredibly inefficient as each call to those tools would require new TLS handshakes with all database servers, tracking down the leader, fetching a new copy of the database, performing a trivial operation and exiting. The new implementation uses a native database client directly in Incus which maintains a constant connection with the database, gets notified of changes and can instantly perform any needed configuration changes.
Then there were 2-3 different cases of database performance issues. Two of them were caused by our auto-generated database helpers which weren’t very smart about handling of profiles, effectively causing a situation where performance would get exponentially worse as more profiles would be present in the database. Addressing this issue resulted in dramatic performance improvement for users operating with hundreds or even thousands of profiles.
Another was related to loading of instances on Incus startup, specifically loading the device definitions to check whether anything needed to be done on startup. This logic was always hitting configuration validation which can be costly, in this case, so costly that Incus would fail to startup during the allotted time by the init system (10 minutes). After some fixes to that logic, the affected system, running over 2000 virtual machines (on a single server) at the time, is now able to process all running VMs in just 10-15s.
On top of those issues, special attention was also put in optimizing resource usage on large systems, especially systems with multiple NUMA nodes, supporting basic NUMA balancing of virtual machines as well as selecting the best GPU devices based on NUMA cost.
Distribution integration
Back at the beginning of 2024, Incus was only available through my own packages for Debian or Ubuntu, or through native packages on Gentoo and NixOS.
This has changed considerably through 2024 with Incus now being readily available on:
Alpine Linux
Arch Linux
Chimera Linux
Debian
Fedora
Gentoo
NixOS
openSUSE
Rocky Linux
Ubuntu
Void Linux
Additionally, it’s also available as a Docker container to run on most any other platforms as well as available on MacOS through Colima. The client tool itself is available everywhere that Go supports.
Deployment tooling
Terraform/OpenTofu provider
The Incus Terraform/OpenTofu provider has seen quite a lot of activity this year.
We’re slowly headed towards a 1.0 release for it, basically ensuring that it can drive every single Incus feature and that its resources are defined in a clear and consistent way.
There is only one issue left in the 1.0 release milestone and there is an open pull request for it, so we are very close to where we want as far as feature coverage and with a few more bugfixes here and there, we should have that 1.0 release out in the coming weeks/month!
incus-deploy
incus-deploy was introduced in February and is basically a collection of Ansible and Terraform that allows for easy deployment of Incus, whether standalone or clustered and whether for testing/development or production.
This is commonly used by the Incus team to quickly deploy test clusters, complete with Ceph, OVN, clustered LVM, … all in a very reproducible way.
Incus OS
While incus-deploy provides an automated way to deploy Incus on top of traditional Linux servers, Incus OS is working on providing a solution for those who don’t want to have to deal with maintaining traditional Linux servers.
This is a fully immutable OS image, kept as minimal as possible and solely focused on running Incus.
It heavily relies on systemd tooling to provide a secure environment, starting from SecureBoot signing, to having every step of the boot be TPM measured, to having storage encrypted using that TPM state and the entire read-only disk image being verified through dm-verity.
The end result is an extremely secure and locked down environment which is designed for just one thing, running Incus!
We’re getting close to having something ready for early adopters with automated builds and update logic now working, but it will be a few more weeks before it’s safe/useful to install on a server.
Where we ended up
Over that year, Incus really turned into a full fledged Open Source project and community.
We have kept on with our release cadence, pushing out a new feature release every month while very actively backporting bugfixes and smaller improvements to our LTS release.
Distributions have done a great job at getting Incus packaged, making it natively available just about everywhere (we’re still waiting on solid EPEL packaging).
Our supporting projects like terraform-provider-incus, incus-deploy and incus-os are making it easier than ever to deploy and operate large scale Incus clusters as well as providing a simpler, more repeatable way of running Incus.
2024 was a very very good year for Incus!
What’s coming in 2025
Looking ahead, 2025 has the potential to be and even better year for us!
On the Incus front, there are no single huge feature to be looking forward to, but just the continual improvement, whether it be for containers, VMs, networking or clustering. We have a lot of small new features and polishing in mind which will help fill in some of the current gaps and provide a nice and consistent experience.
But it’s on the supporting projects that a lot of the potential now rests.
This will hopefully be the year of Incus OS, making installing Incus as easy as writing a file to a USB stick, booting a machine from it and accessing it over the network. Want to make a cluster, no problem, just boot a few more machines onto Incus OS and join them together as a cluster!
But we’re also going to be expanding incus-deploy. It’s currently doing a good job at deploying Incus on Ubuntu servers with Ansible but we want to expand that to also cover Debian and some of the RHEL derivatives so we can cover the majority of our current production users with it. On top of that, we want to also have incus-deploy handle setting up the common support services used by Incus clusters, typically OpenFGA, Keycloak, Grafana, Prometheus and Loki.
We also want to improve our testing and development lab, add more systems, add the ability to test on more architectures and easily test more complex features, whether it’s 100Gb/s+ networking with full hardware offload or confidential computing features like AMD SEV.
Sovereign Tech Fund
Thankfully a lot of that is going to be made a whole lot easier thanks to funding by the Sovereign Tech Fund who’s going to be supporting a variety of Incus related projects, especially focusing on the kind of work that’s not particularly exciting but is very much critical to the proper running of a project like ours.
This includes a big refresh of our testing and development lab, work on our LTS releases, new security features through the stack, improved support for other Linux distributions and OSes across our projects and more!




 Github
Github Twitter
Twitter LinkedIn
LinkedIn Mastodon
Mastodon