
Over the past few posts, I covered the hardware I picked up to setup a small LXD cluster and get it all setup at a co-location site near home. I’ve then gone silent for about 6 months, not because anything went wrong but just because of not quite finding the time to come back and complete this story!
So let’s pick things up where I left them with the last post and cover the last few bits of the network setup and then go over what happened over the past 6 months.
Routing in a HA environment
You may recall that the 3 servers are both connected to a top of the rack switch (bonded dual-gigabit) as well as connected to each other (bonded dual-10-gigabit). The netplan config in the previous post would allow each of the servers to talk to the others directly and establish a few VLANs on the link to the top of the rack switch.
Those are for:
- WAN-HIVE: Peering VLAN with my provider containing their core routers and mine
- INFRA-UPLINK: OVN uplink network (where all the OVN virtual routers get their external addresses)
- INFRA-HOSTS: VLAN used for external communication with the servers
- INFRA-BMC: VLAN used for the management ports of the servers (BMCs) and switch, isolated from the internet
Simply put, the servers have their main global address and default gateway on INFRA-HOSTS, the BMCs and switch have their management addresses in INFRA-BMC, INFRA-UPLINK is consumed by OVN and WAN-HIVE is how I access the internet.
In my setup, I then run three containers, one on each server which each gets direct access to all those VLANs and act as a router using FRR. FRR is configured to establish BGP sessions with both of my provider’s core routers, getting routing to the internet that way and announcing my IPv4 and IPv6 subnets that way too.
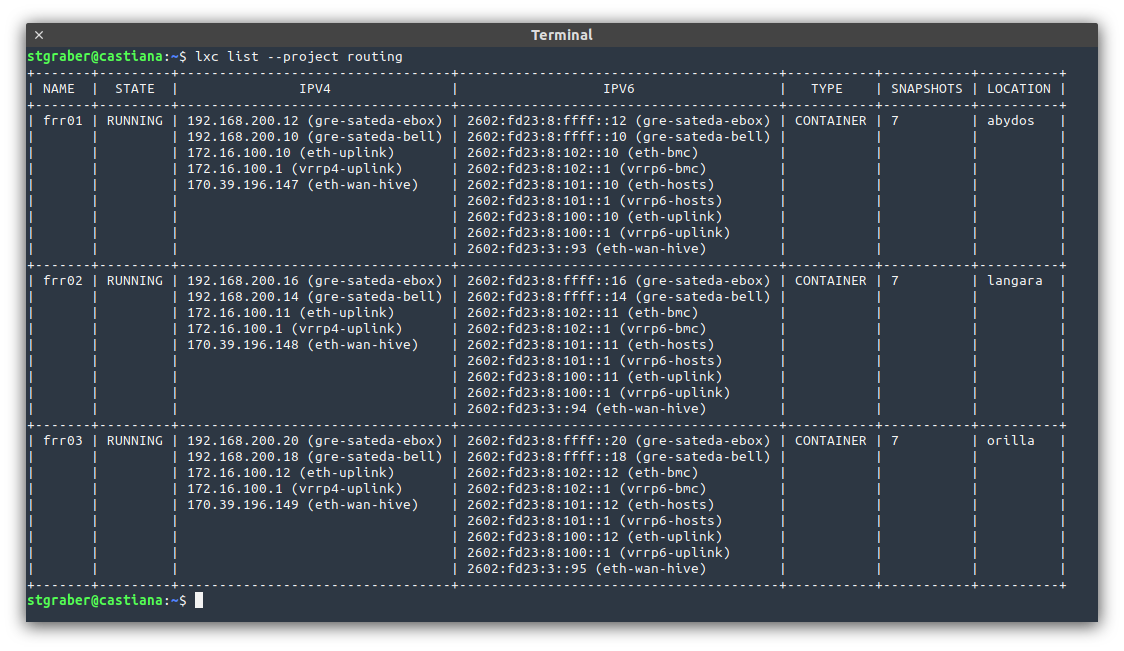
On the internal side of things, I’m using VRRP to provide a virtual router internally. Typically this means that frr01 is the default gateway for all egress traffic while ingress traffic is somewhat spread across all 3 thanks to them having the same BGP weight (so my provider’s routers distribute the connections across all active peers).
With that in place, so long as one of the FRR instances are running, connectivity is maintained. This makes doing maintenance quite easy as there is effectively no SPOF.
Enter LXD networks with OVN
Now for where things get a bit trickier. As I’m using OVN to provide virtual networks inside of LXD, each of those networks will typically need some amount of public addressing. For IPv6, I don’t do NAT so each of my networks get a public /64 subnet. For IPv4, I have a limited number of those, so I just assign them one by one (/32) directly to specific instances.
Whenever such a network is created, it will grab an IPv4 and IPv6 address from the subnet configured on INFRA-UPLINK. That part is all good and the OVN gateway becomes immediately reachable.
The issue is with the public IPv6 subnet used by each network and with any additional addresses (IPv4 or IPv6) which are routed directly to its instances. For that to work, I need my routers to send the traffic headed for those subnets to the correct OVN gateway.
But how do you do that? Well, there are pretty much three options here:
- You use LXD’s default mode of performing NDP proxying. Effectively, LXD will configure OVN to directly respond to ARP/NDP on the INFRA-UPLINK VLAN as if the gateway itself was holding the address being reached.
This is a nice trick which works well at pretty small scale. But it relies on LXD configuring a static entry for every single address in the subnet. So that’s fine for a few addresses but not so much when you’re talking a /64 IPv6 subnet. - You add static routing rules to your routers. Basically you run
lxc network show some-nameand look for the IPv4 and IPv6 addresses that the network got assigned, then you go on your routers and you configure static routes for all the addresses that need to be sent to that OVN gateway. It works, but it’s pretty manual and effectively prevents you from delegating network creation to anyone who’s not the network admin too. - You use dynamic routing to have all public subnets and addresses configured on LXD to be advertised to the routers with the correct next-hop address. With this, there is no need to configure anything manually, keeping the OVN config very simple and allowing any user of the cluster to create their own networks and get connectivity.
Naturally I went with the last one. At the time, there was no way to do that through LXD, so I made my own by writing lxd-bgp. This is a pretty simple piece of software which uses the LXD API to inspect its networks, determine all OVN networks tied to a particular uplink network (INFRA-UPLINK in my case) and then inspect all instances running on that network.
It then sends announcements both for the subnets backing each OVN networks as well as for specific routes/addresses that are routed on top of that to specific instances running on the local system.
The result is that when an instance with a static IPv4 and IPv6 starts, the lxd-bgp instance running on that particular system will send an announcement for those addresses and traffic will start flowing.
Now deploy the same service on 3 servers, put them into 3 different LXD networks and set the exact same static IPv4 and IPv6 addresses on them and you now have a working anycast service. When one of the containers or its host go down for some reason, that route announcement goes away and the traffic now heads to the remaining instances. That does a good job at some simplistic load-balancing and provides pretty solid service availability!
The past 6 months
Now that we’ve covered the network setup I’m running, let’s spend a bit of time going over what happened over the past 6 months!

In short, well, not a whole lot. Things have pretty much just been working. The servers were installed in the datacenter on the 21st of December. I’ve then been busy migrating services from my old server at OVH over to the new cluster, finalizing that migration at the end of April.
I’ve gotten into the habit of doing a full reboot of the entire cluster every week and developed a bit of tooling for this called lxd-evacuate. This makes it easy to relocate any instance which isn’t already highly available, emptying a specific machine and then letting me reboot it. By and large this has been working great and it’s always nice to have confidence that should something happen, you know all the machines will boot up properly!
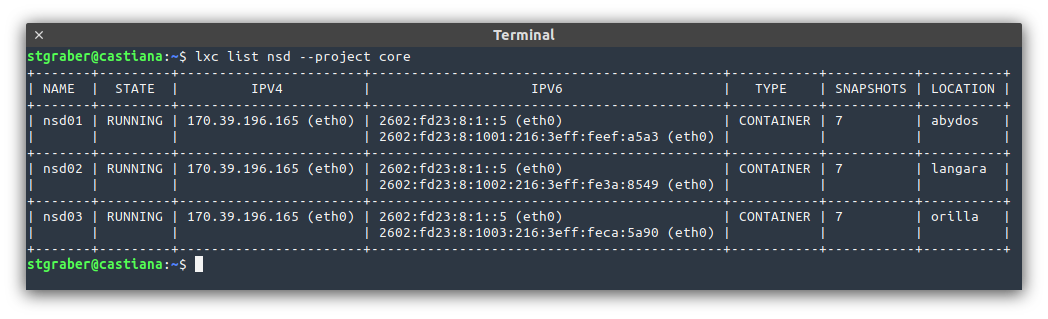
These days, I’m running 63 instances across 9 projects and a dozen networks. I spent a bit of time building up a Grafana dashboard which tracks and alerts on my network consumption (WAN port, uplink to servers and mesh), monitors the health of my servers (fan speeds, temperature, …), tracks CEPH consumption and performance, monitors the CPU, RAM and load of each of the servers and also track performance on my top services (NSD, unbound and HAProxy).
LXD also rolled out support for network ACLs somewhat recently, allowing for proper stateful firewalling directly through LXD and implemented in OVN. It took some time to setup all those ACLs for all instances and networks but that’s now all done and makes me feel a whole lot better about service security!
What’s next
On the LXD front, I’m excited about a few things we’re doing over the next few months which will make environments like mine just that much nicer:
- Native BGP support (no more lxd-bgp)
- Native cluster server evacuation (no more lxd-evacuate)
- Built-in DNS server for instance forward/reverse records as well as DNS zones tied to networks
- Built-in metrics (prometheus) endpoint exposing CPU/memory/disk/network usage of all local instances
This will let me deprecate some of those side projects I had to start as part of this work, will reduce the amount of manual labor involved in setting up all the DNS records and will give me much better insight on what’s consuming resources on the cluster.
I’m also in the process of securing my own ASN and address space through ARIN, mostly because that seemed like a fun thing to do and will give me a tiny bit more flexibility too (not to mention let me consolidate a whole bunch of subnets). So soon enough, I expect to have to deal with quite a bit of re-addressing, but I’m sure it will be a fun and interesting experience!


 Github
Github Twitter
Twitter LinkedIn
LinkedIn Mastodon
Mastodon