
In the previous post I went over the reasons for switching to my own hardware and what hardware I ended up selecting for the job.
Now it’s time to look at how I intend to achieve the high availability goals of this setup. Effectively limiting the number of single point of failure as much as possible.
Hardware redundancy

On the hardware front, every server has:
- Two power supplies
- Hot swappable storage
- 6 network ports served by 3 separate cards
- BMC (IPMI/redfish) for remote monitoring and control
The switch is the only real single point of failure on the hardware side of things. But it also has two power supplies and hot swappable fans. If this ever becomes a problem, I can also source a second unit and use data and power stacking along with MLAG to get rid of this single point of failure.
I mentioned that each server has four 10Gbit ports yet my switch is Gigabit. This is fine as I’ll be using a mesh type configuration for the high-throughput part of the setup. Effectively connecting each server to the other two with a dual 10Gbit bond each. Then each server will get a dual Gigabit bond to the switch for external connectivity.
Software redundancy
The software side is where things get really interesting, there are three main aspects that need to be addressed:
- Storage
- Networking
- Compute
Storage
For storage, the plan is to rely on Ceph, each server will run a total of 4 OSDs, one per physical drive with the SATA SSD acting as boot drive too with the OSD being a large partition on it instead of the full disk.
Each server will also act as MON, MGR and MDS providing a fully redundant Ceph cluster on 3 machines capable of providing both block and filesystem storage through RBD and FS.
Two maps will be setup, one for HDD storage and one for SSD storage.
Storage affinity will also be configured such that the NVME drives will be used for the primary replica in the SSD map with the SATA drives holding secondary/tertiary replicas instead.
This makes the storage layer quite reliable. A full server can go down with only minimal impact. Should a server being offline be caused by hardware failure, the on-site staff can very easily relocate the drives from the failed server to the other two servers allowing Ceph to recover the majority of its OSDs until the defective server can be repaired.
Networking
Networking is where things get quite complex when you want something really highly available. I’ll be getting a Gigabit internet drop from the co-location facility on top of which a /27 IPv4 and a /48 IPv6 subnet will be routed.
Internally, I’ll be running many small networks grouping services together. None of those networks will have much in the way of allowed ingress/egress traffic and the majority of them will be IPv6 only.
The majority of egress will be done through a proxy server and IPv4 access will be handled through a DNS64/NAT64 setup.
Ingress when needed will be done by directly routing an additional IPv4 or IPv6 address to the instance running the external service.
At the core of all this will be OVN which will run on all 3 machines with its database clustered. Similar to Ceph for storage, this allows machines to go down with no impact on the virtual networks.
Where things get tricky is on providing a highly available uplink network for OVN. OVN draws addresses from that uplink network for its virtual routers and routes egress traffic through the default gateway on that network.
One option would be for a static setup, have the switch act as the gateway on the uplink network, feed that to OVN over a VLAN and then add manual static routes for every public subnet or public address which needs routing to a virtual network. That’s easy to setup, but I don’t like the need to constantly update static routing information in my switch.
Another option is to use LXD’s l2proxy mode for OVN, this effectively makes OVN respond to ARP/NDP for any address it’s responsible for but then requires the entire IPv4 and IPv6 subnet to be directly routed to the one uplink subnet. This can get very noisy and just doesn’t scale well with large subnets.
The more complicated but more flexible option is to use dynamic routing.
Dynamic routing involves routers talking to each other, advertising and receiving routes. That’s the core of how the internet works but can also be used for internal networking.
My setup effectively looks like this:
- Three containers running FRR each connected to both the direct link with the internet provider and to the OVN uplink network.
- Each one of those will maintain BGP sessions with the internet provider’s routers AS WELL as with the internal hosts running OVN.
- VRRP is used to provide a single highly available gateway address on the OVN uplink network.
- I wrote lxd-bgp as a small BGP daemon that integrates with the LXD API to extract all the OVN subnets and instance addresses which need to be publicly available and announces those routes to the three routers.
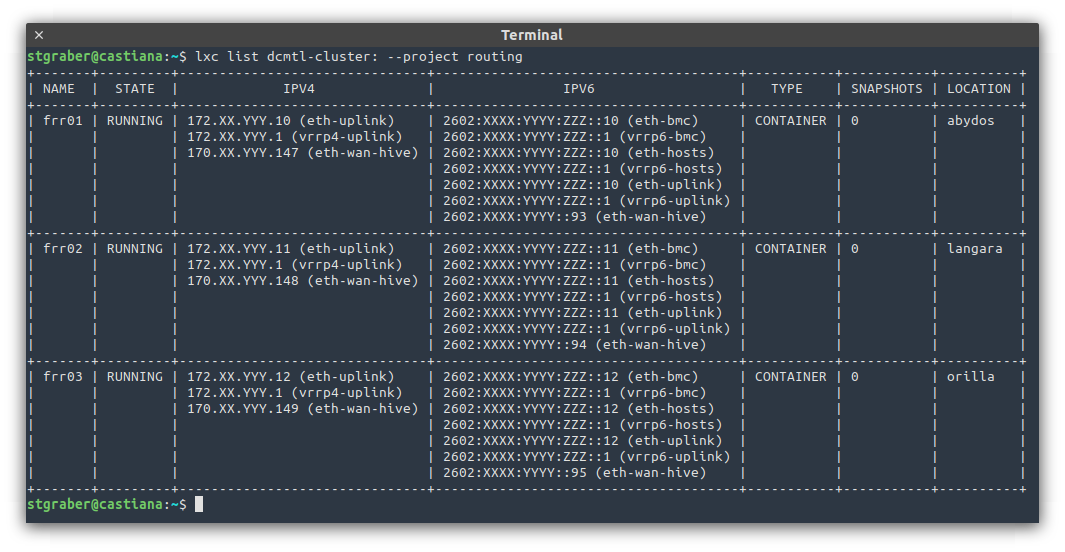
This may feel overly complex and it quite possibly is, but that gives me three routers, one on each server and only one of which need to be running at any one time. It also gives me the ability to balance routing traffic both ingress or egress by tweaking the BGP or VRRP priorities.
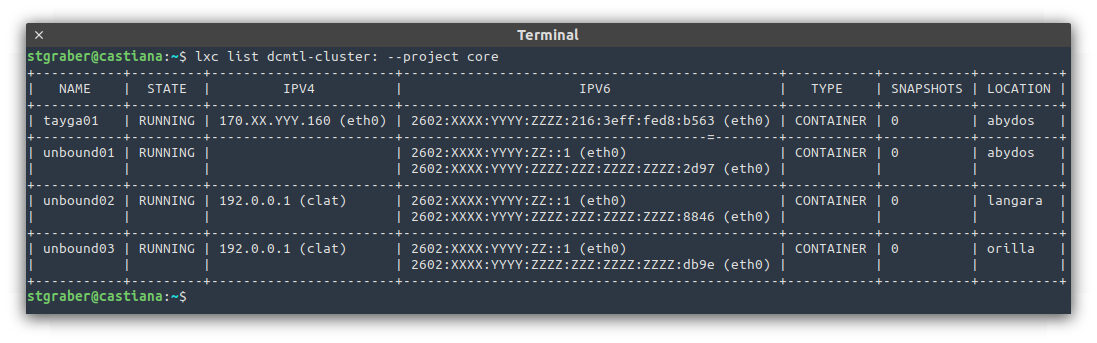
The nice side effect of this setup is that I’m also able to use anycast for critical services both internally and externally. Effectively running three identical copies of the service, one per server, all with the exact same address. The routers will be aware of all three and will pick one at the destination. If that instance or server goes down, the route disappears and the traffic goes to one of the other two!
Compute
On the compute side, I’m obviously going to be using LXD with the majority of services running in containers and with a few more running in virtual machines.
Stateless services that I want to always be running no matter what happens will be using anycast as shown above. This also applies to critical internal services as is the case above with my internal DNS resolvers (unbound).
Other services may still run two or more instances and be placed behind a load balancing proxy (HAProxy) to spread the load as needed and handle failures.
Lastly even services that will only be run by a single instance will still benefit from the highly available environment. All their data will be stored on Ceph, meaning that in the event of a server maintenance or failure, it’s a simple matter of running lxc move to relocate them to any of the others and bring them back online. When planned ahead of time, this is service downtime of less than 5s or so.
Up next
In the next post, I’ll be going into more details on the host setup, setting up Ubuntu 20.04 LTS, Ceph, OVN and LXD for such a cluster.
 Github
Github Twitter
Twitter LinkedIn
LinkedIn Mastodon
Mastodon
cool
Looks good. Glad to see FRR in use. I also use this.
The BGP part above is kinda similar to how metal-lb pods function in kubernetes, advertising /32 host routes (anycast / ecmp) to the upstream gateway from each host. Each /32 maps to an internal service in the downstream kubernetes hosts. Allows for decent failover and load balancing between all the hosts.
Cheers!
Jon.