And as always, my company is offering commercial support on Incus, ranging from by-the-hour support contracts to one-off services on things like initial migration from LXD, review of your deployment to squeeze the most out of Incus or even feature sponsorship. You’ll find all details of that here: https://zabbly.com/incus
Donations towards my work on this and other open source projects is also always appreciated, you can find me on Github Sponsors, Patreon and Ko-fi.
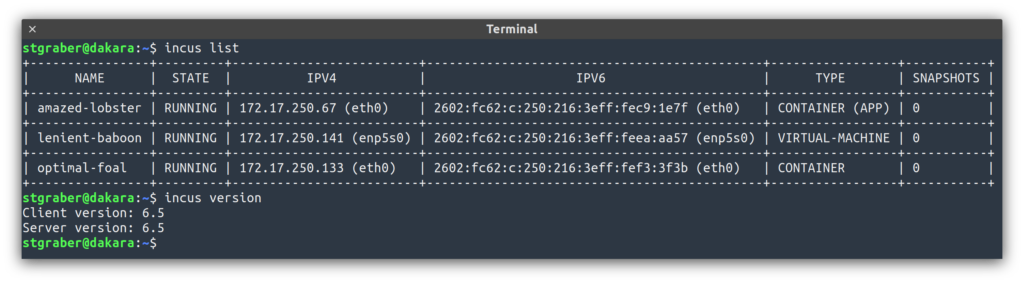
This release builds upon the recently added OCI support from Incus 6.3, making it even easier to run application containers. It also adds a number of useful new features for clustered and larger environments with more control on the virtual CPU used when live migrating VMs and finer grained resource constraints within projects.
The highlights for this release are:
Cluster group configuration
Per-cluster group CPU baseline
Attaching sub-directories of custom storage volumes
Per storage pool project limits
Isolated OVN networks (no uplink)
Per-instance LXCFS
Environment files at create/launch time
The full announcement and changelog can be found here. And for those who prefer videos, here’s the release overview video:
And as always, my company is offering commercial support on Incus, ranging from by-the-hour support contracts to one-off services on things like initial migration from LXD, review of your deployment to squeeze the most out of Incus or even feature sponsorship. You’ll find all details of that here: https://zabbly.com/incus
Donations towards my work on this and other open source projects is also always appreciated, you can find me on Github Sponsors, Patreon and Ko-fi.
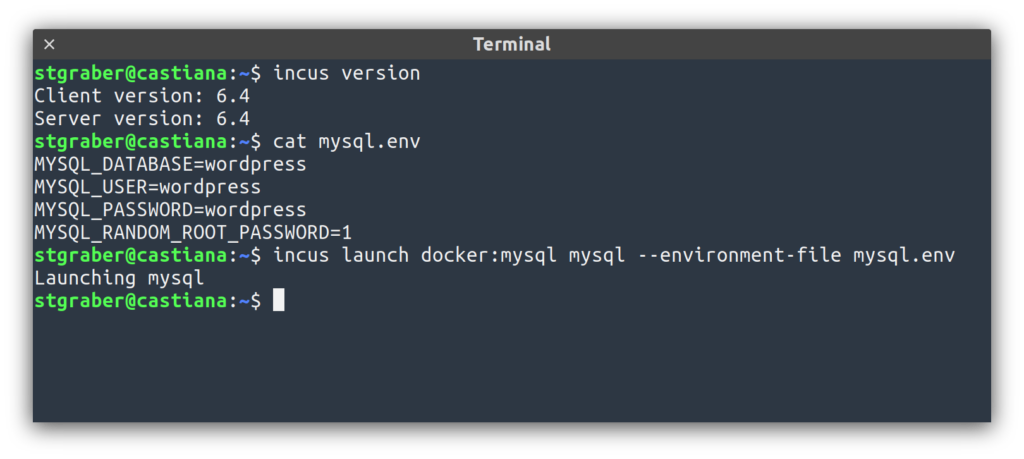
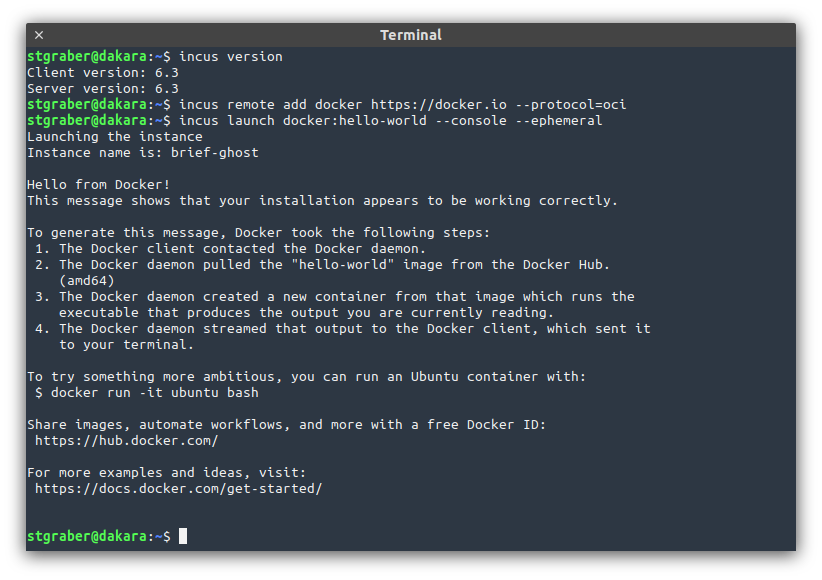
This release includes the long awaited OCI/Docker image support! With this, users who previously were either running Docker alongside Incus or Docker inside of an Incus container just to run some pretty simple software that’s only distributed as OCI images can now just do it directly in Incus.
In addition to the OCI container support, this release also comes with:
Baseline CPU definition within clusters
Filesystem support for io.bus and io.cache
Improvements to incus top
CPU flags in server resources
Unified image support in incus-simplestreams
Completion of libovsdb transition
The full announcement and changelog can be found here. And for those who prefer videos, here’s the release overview video:
And as always, my company is offering commercial support on Incus, ranging from by-the-hour support contracts to one-off services on things like initial migration from LXD, review of your deployment to squeeze the most out of Incus or even feature sponsorship. You’ll find all details of that here: https://zabbly.com/incus
Donations towards my work on this and other open source projects is also always appreciated, you can find me on Github Sponsors, Patreon and Ko-fi.
Zabbly is the company I created for my freelance work. Over the year, a number of my personal projects were transferred over to being part of Zabbly, including the operation of my ASN (as399760.net), my datacenter co-location infrastructure and more.
Through Zabbly I offer a mix of by-the-hour consultation with varying prices depending on the urgency of the work (basic consultation, support, emergency support) as well as fixed-cost services, mostly related to Incus (infrastructure review, migration from LXD, remote or on-site trainings, …).
Other than Incus, Zabbly also provides up to date mainline kernel packages for Debian and Ubuntu and associated up to date ZFS packages. This is something that came out as needed for a number of projects I work on, from being able to test Incus on recent Linux kernels to avoiding Ubuntu kernel bugs on my own and NorthSec’s servers.
Zabbly is also the legal entity for donations related to my open source work, currently supporting:
And lastly, Zabbly also runs a Youtube channel covering the various projects I’m involved with. A lot of it is currently about Incus, but there is also the occasional content on NorthSec or other side projects. The channel grew to a bit over 800 subscribers in the past 10 months or so.
Now, how well is all of that doing? Well enough that I could stop relying on my savings just a few months in and turn a profit by the end of 2023. Zabbly currently has around a dozen active customers from 7 countries and across 3 continents with size ranging from individuals to large governmental agencies.
2024 has also been very good so far and while I’m not back to the level of income I had while at Canonical, I also don’t have to go through 4-5 hours of meetings a day and get to actually contribute to open source again, so I’ll gladly take the (likely temporary) pay cut!
Incus
A lot of my time in the past year has been dedicated to Incus.
This wasn’t exactly what I had planned when leaving Canonical. I was expecting LXD to keep on going as a proper Open Source project as part of the Linux Containers community. But Canonical had other plans and so things changed a fair bit over the few months following my departure.
For those not aware, the rough timeline of what happened is:
So rather than contributing to LXD while working on some other new projects, a lot of my time has instead gone into setting up the Incus project for success.
And I think I’ve been pretty successful at that as we’re seeing a monthly user base growth (based on image server interactions) of around 25%. Incus is now natively available in most Linux distributions (Alpine, Arch Linux, Debian, Gentoo, Nix, Ubuntu and Void) with more coming soon (Fedora and EPEL).
Incus has 6 maintainers, most of whom were the original LXD maintainers. We’ve seen over 100 individual contributors since Incus was forked from LXD including around 20 students from the University of Texas in Austin who contributed to Incus as part of their virtualization class.
I’ve been acting as the release manager for Incus, also running all the infrastructure behind the project, mentoring new contributors and reviewing a number of changes while also contributing a number of new features myself, some sponsored by my customers, some just based on my personal interests.
A big milestone for Incus was its 6.0 LTS release as that made it suitable for production users. Today we’re seeing around 40% of our users running the LTS release while the rest run the monthly releases.
As mentioned in my recent post about the 6.0.1 LTS releases, the Linux Containers project tries to do coordinated LTS releases on our core projects. This currently includes LXC, LXCFS and Incus.
I didn’t have to do too much work myself on LXC and LXCFS, thanks to Aleksandr Mikhalitsyn from the Canonical LXD team who’s been dealing with most of the review and issues in both LXC and LXCFS alongside other long time maintainers, Serge Hallyn and Christian Brauner.
NorthSec
NorthSec is a yearly cybersecurity conference, CTF and training provider, usually happening in late May in Montreal, Canada. It’s been operating since 2013 and is now one of the largest on-site CTF events in the world along with having a pretty sizable conference too.
I’m the current VP of Infrastructure for the event and have been involved with it from the beginning, designing and running its infrastructure, first on a bunch of old donated hardware and then slowly modernizing that to the environment we have now with proper production hardware both at our datacenter and on-site during the event.
This year, other than transitioning everything from LXD to Incus, the main focus has been on upgrading the OS on our 6 physical servers and dozens of infrastructure containers and VMs from Ubuntu 20.04 LTS to Ubuntu 24.04 LTS.
At the same time, also significantly reducing the complexity of our infrastructure by operating a single unified Incus cluster, switching to OpenID Connect and OpenFGA for access control and automating even more of our yearly infrastructure with Ansible and Terraform.
Automation is really key with NorthSec as it’s a non-profit organization with a lot of staffing changes every year, around 100 year long contributors and then an additional 50 or so on-site volunteers!
I went over the NorthSec infrastructure in a couple of YouTube videos:
I’ve cut down and focused my conference attendance a fair bit over this past year. Part of it for budgetary reasons, part of it because of having so many things going on that fitting another couple of weeks of cross-country travel was difficult.
I decided to keep attending two main events. The Linux Plumbers Conference where I co-organizer the Containers and Checkpoint-Restore Micro-Conference and FOSDEM where I co-organize both the Containers and the Kernel devrooms.
With one event usually in September/October and the other in February, this provides two good opportunities to catch up with other developers and users, get to chat a bunch and make plans for the year.
I’m looking forward to catching up with folks at the upcoming Linux Plumbers Conference in Vienna, Austria!
What’s next
I’ve got quite a lot going on, so the remaining half of 2024 and first half of 2025 are going to be quite busy and exciting!
On the Incus front, we’ve got some exciting new features coming in, like the native OCI container support, more storage options, more virtual networking features, improved deployment tooling, full coverage of Incus features in Terraform/OpenTofu and even a small immutable OS image!
NorthSec is currently wrapping up a few last items related to its 2024 edition and then it will be time to set up the development infrastructure and get started on organizing 2025!
For conferences, as mentioned above, I’ll be in Vienna, Austria in September for Linux Plumbers and expect to be in Brussels again for FOSDEM in February.
There’s also more that I’m not quite ready to talk about, but expect some great Incus related news to come out in the next few months!
The Linux Containers project maintains Long Term Support (LTS) releases for its core projects. Those come with 5 years of support from upstream with the first two years including bugfixes, minor improvements and security fixes and the remaining 3 years getting only security fixes.
Our current LTS release, 6.0, is as the name implies the 6th time we’ve released an LTS release of our projects, starting over 10 years ago, in February 2014.
At the time of writing, we have three currently supported LTS releases:
4.0 (supported until June 2025, security-only)
5.0 (supported until June 2027, security-only)
6.0 (supported until June 2029).
The 6.0 LTS release begun in April 2024 and was the first to include Incus.
LXC
LXC is the oldest Linux Containers project and the basis for almost every other one of our projects. This low-level container runtime and library was first released in August 2008, led to the creation of projects like Docker and today is still actively used directly or indirectly on millions of systems.
Fixed startup failures on system without IPv6 support
Updated AppArmor rules to avoid potential warnings
LXCFS
LXCFS is a FUSE filesystem used to workaround some shortcomings of the Linux kernel when it comes to reporting available system resources to processes running in containers. The project started in late 2014 and is still actively used by Incus today as well as by some Docker and Kubernetes users.
Unfortunately the LXCFS approach is starting to run into issues due to tools relying more and more on system call interfaces or other methods to obtain resource information these days requiring more complex solution such as Incus’ system call interception support (using the Seccomp Notifier).
Because of that development, we’ve been slowly discussing better ways to provide reliable resource information to userspace without having to rely on filesystem tricks or costly system call interception, but as with anything that requires widespread userspace adoption, it will take a while until such a solution is in place and so LXCFS isn’t going anywhere any time soon!
Support for running multiple instances of LXCFS (--runtime-dir)
Detect systems that has a Yama policy preventing reading process personalities
Incus
Incus is our most actively developed project. This virtualization platform is less than a year old but has already seen over 3000 commits by over 100 individual contributors. Its first LTS release made it usable in production environments and significantly boosted its user base.
Extended source syntax for ZFS pools (allows mirror & raidz1/raidz2)
Cross-project listing on all objects (instances, profiles, images, storage volumes/buckets, networks, …)
Additional functions exposed to instance placement scriptlet
All create sub-commands in the CLI now accept YAML input
All list sub-commands in the CLI now accept customizable columns
The migration.stateful config key was expanded to containers too
Stateless network ACLs are now supported on OVN
New timestamp exposed for instance uptime
New incus top command (uses existing metric API)
System load information in incus info --resources
PCI devices information in incus info --resources
Ability to query who has access to a given project or instance
Forceful deletion of projects
Improved alias handling in incus-simplestreams
What’s next?
We’re going to keep backporting all relevant fixes and minor improvements to our LTS branches and will likely be releasing another LTS point release of those 3 projects later this year.
There is no set schedule on LTS point releases as we instead prefer to wait until we feel there are significant enough fixes to warrant one, then make sure that all three projects are properly tested and ready for a release.
This year we’ve also decided to start releasing non-LTS releases of both LXC and LXCFS. It’s something we used to do some years ago but then stopped, mostly due to lack of time. So you can look forward to LXC and LXCFS 6.1 in Q4 of 2024!



 Github
Github Twitter
Twitter LinkedIn
LinkedIn Mastodon
Mastodon