
The Incus team is pleased to announce the release of Incus 6.16!
This release brings in a new storage driver, the ability to install Windows VMs without having to rely on a repacked ISO and support for temporary storage in containers.
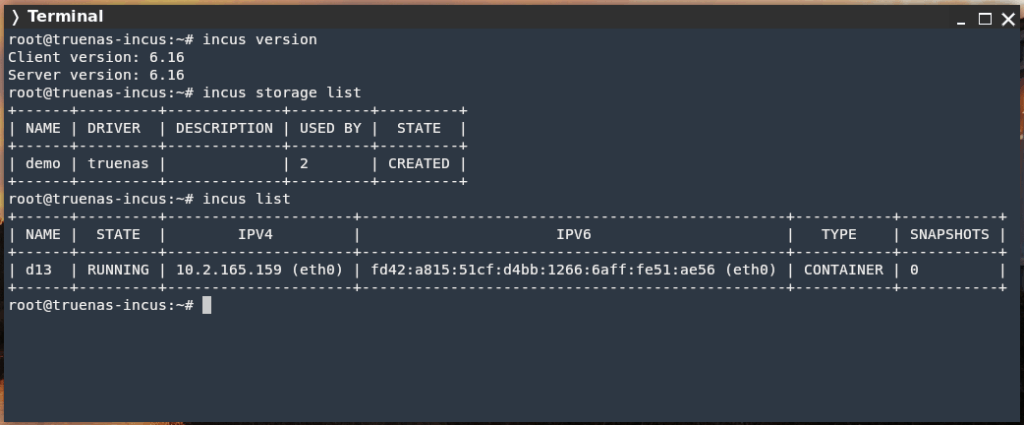
The highlights for this release are:
- TrueNAS storage driver
- USB CD-ROM handling for VMs
- tmpfs and tmpfs-overlay disks for containers
- Configurable console behavior in the CLI
The full announcement and changelog can be found here.
And for those who prefer videos, here’s the release overview video:
You can take the latest release of Incus up for a spin through our online demo service at: https://linuxcontainers.org/incus/try-it/
And as always, my company is offering commercial support on Incus, ranging from by-the-hour support contracts to one-off services on things like initial migration from LXD, review of your deployment to squeeze the most out of Incus or even feature sponsorship. You’ll find all details of that here: https://zabbly.com/incus
Donations towards my work on this and other open source projects is also always appreciated, you can find me on Github Sponsors, Patreon and Ko-fi.
Enjoy!
 Github
Github Twitter
Twitter LinkedIn
LinkedIn Mastodon
Mastodon