
Ubuntu 24.04 LTS was released just a few days ago and many Ubuntu users will now slowly plan their upgrades, whether it’s going to be over the next few days, weeks, months or years.
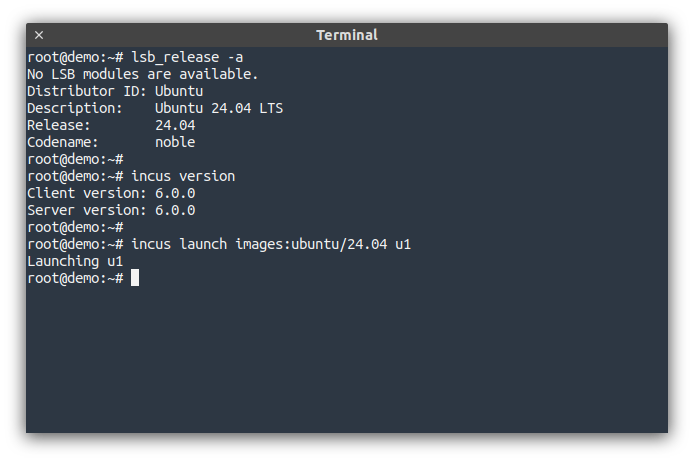
When it comes to running Incus on Ubuntu 24.04 LTS, there are a few options detailed below.
About Incus
Incus is a container and virtual machine manager which aims at providing a cloud-like experience but fully self-hosted and capable of running on just about anything, from a single board computer, to a laptop to a cluster of high end servers.
Incus was created following Canonical’s decision to make LXD a fully in-house project and it is actively maintained by the same team that once created LXD, almost 10 years ago. It’s part of the Linux Containers project and so benefits of all the infrastructure and experience in maintaining stable software over decades.
Native Incus packages
Incus 6.0 LTS is included directly in the Ubuntu Archive, making it very easy to install:
- Simple container experience:
apt install incus - Container and virtual-machines:
apt install incus qemu-system-x86-64 - To migrate from LXD:
apt install incus-tools
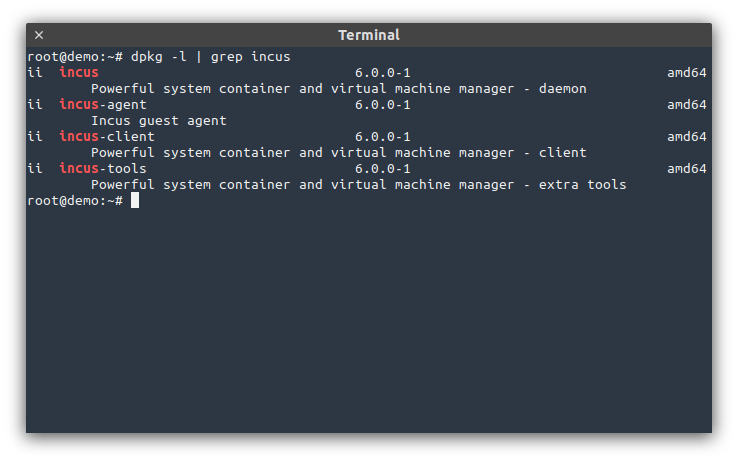
Installing Incus that way is convenient as it doesn’t use external repositories nor does it rely on alternative packaging methods like snaps. That’s also the same set of Incus packages that will be shipped with Debian 13 (Trixie).
On the support front, this is using Incus 6.0 LTS and so uses a version of Incus that will be supported upstream for the next 5 years. The package itself is in the universe repository and so doesn’t come with security updates provided by Canonical as part of stock Ubuntu.
However Canonical now provides additional security updates to Ubuntu Pro users which includes both security updates and support for all 23000 packages in universe.
Third party Incus packages
An alternative is to use the packages that I produce myself.
Those packages are quite different from the ones shipped directly in Ubuntu or Debian as they also directly include the most critical dependencies so that the whole solution can be tested and validated as a single unit.
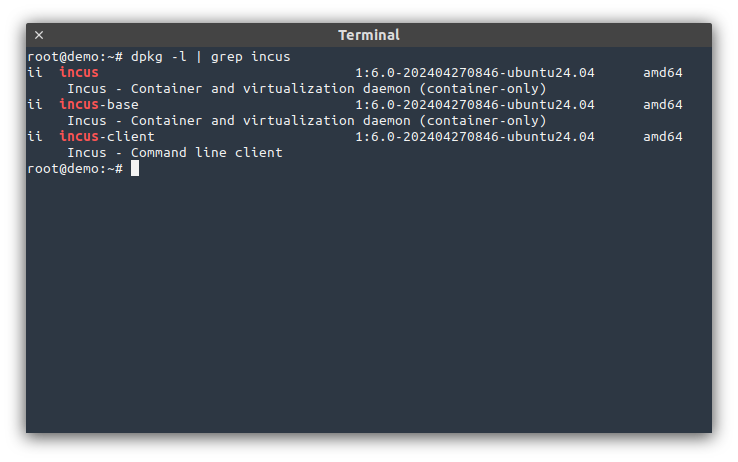
That makes it much easier for me to provide timely fixes as well as commercial support for users of those packages. It also allows for decoupling the Incus installation/version from the OS version, making major system updates easier.
Packages are available for Ubuntu 20.04, 22.04 and now 24.04 LTS as well as Debian 11 and Debian 12.
Moving from LXD
Ubuntu 24.04 LTS ships with LXD 5.21, migrating from LXD 5.21 to Incus 6.0 LTS can be done very easily by running the “lxd-to-incus” command.

It supports very quickly and reliably migrating data from LXD installations as old as LXD 4.0.0 all the way to and including LXD 5.21.
Running Ubuntu 24.04 LTS on top of Incus
If you’re just looking at using Ubuntu 24.04 LTS but don’t want to upgrade your whole system yet, or you’re running another Linux distribution and just want to experiment with Ubuntu 24.04 LTS, you can easily do that through Incus.
Incus has the following images ready for use:
Ubuntu 24.04 LTS base image
Our default Ubuntu 24.04 LTS image. It’s pretty lightweight while still containing most expected tools for day to day operation.
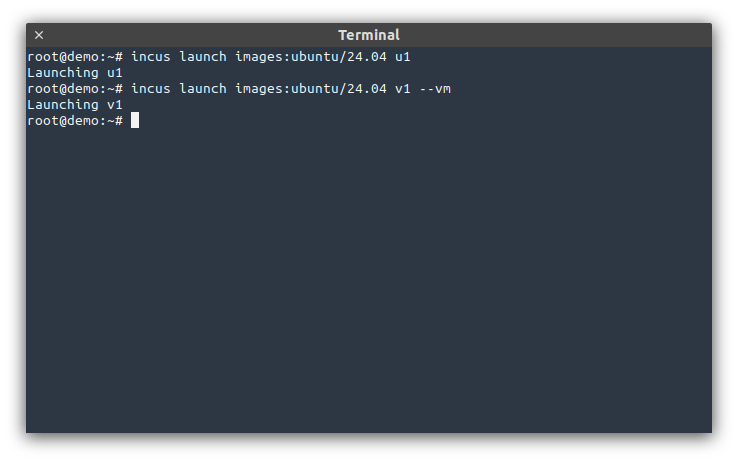
It’s available for both containers (125MiB compressed) and virtual-machines (270MiB compressed).
Ubuntu 24.04 LTS cloud image
Our cloud-init enabled Ubuntu 24.04 LTS image, it’s basically the same as the default image but with cloud-init enabled for automated provisioning.
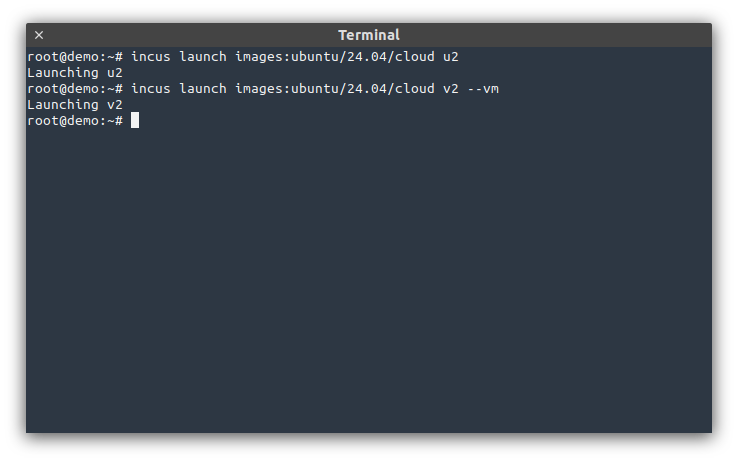
It’s available for both containers (150MiB compressed) and virtual-machines (305MiB compressed).
Ubuntu 24.04 LTS desktop image
Our desktop (Gnome) Ubuntu 24.04 LTS image, it boots directly into a pre-created user account and makes it extremely easy to try the latest Ubuntu Desktop experience.
This image is only available as a virtual-machine (1.1GiB compressed).
Conclusion
Hopefully this provided a pretty good overview of how to get Incus up and running on Ubuntu 24.04 LTS, either by moving from an existing LXD installation over to Incus or installing it fresh.
If you’d just like to learn more about Incus without having to install it locally, our online demo service is as great for that as ever!
And if you’re not using Ubuntu on your system, don’t worry, Incus can run on just about anything else too!
 Github
Github Twitter
Twitter LinkedIn
LinkedIn Mastodon
Mastodon